En la pandemia generada por la Covid-19, que desde hace ya más de un año ha cambiado nuestras vidas y nos está obligando a gestionar el mayor reto al que nuestro sistema sanitario -y nuestra sociedad- se ha enfrentado en las últimas décadas, todas las armas son pocas para ir ganando terreno al coronavirus.
En este contexto, la última herramienta con la que los Hospitales Públicos gestionados por Quirónsalud en la Comunidad de Madrid -los hospitales universitarios Fundación Jiménez Díaz (Madrid), Rey Juan Carlos (Móstoles), Infanta Elena (Valdemoro) y General de Villalba (Collado Villalba)- cuentan para luchar contra la Covid-19 es más que bienvenida: un algoritmo predictivo basado en el Big Data que permite pronosticar en tiempo real la progresión de muchos pacientes afectados por el coronavirus.
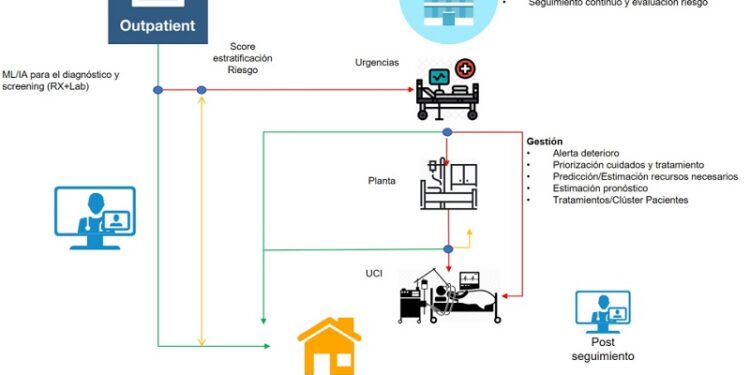
Concretamente, el sistema, diseñado el pasado mes de mayo y puesto en marcha desde septiembre en estos cuatro centros, ofrece un patrón de comportamiento que, tal y como explica Antonio Herrero González, responsable de Big Data de esta red asistencial, permite prever la evolución, en términos de mortalidad y de empeoramiento (riesgo de ingreso en la Unidad de Cuidados Intensivos, UCI, en las siguientes horas), de aquellos pacientes Covid hospitalizados que cumplen determinados criterios.
382 variables analizadas y más de 15.000 pacientes
El algoritmo parte de la recogida de parámetros como los datos demográficos del paciente (edad, sexo, si son o no de residencias…), sus antecedentes personales (si es fumador o diabético, si tiene hipertensión o problemas cardiovasculares, pulmonares, neurológicos, oncológicos, renales, etc), fármacos administrados (antes y en el momento del ingreso), otras variables como el grupo sanguíneo, el Índice de Masa Corporal (IMC), si ha estado previamente en la UCI o ha sido sometido a ventilación mecánica, y hasta 382 variables de laboratorio y su evolución temporal.
“El análisis de esta información en los más de 15.000 pacientes Covid que estuvieron hospitalizados en estos cuatro hospitales desde la primera ola y el inicio de la segunda, mediante el empleo de métodos de machine learning, permitió seleccionar las variables más relevantes, un total de 20, que ofrecen patrones de comportamiento de los pacientes positivos a través de los cuales se puede prever su evolución”, señala Herrero.
Una herramienta que “permite constatar estos patrones con datos clínicos, mejorando la calidad y seguridad del proceso, y que ofrece una información adicional de gran utilidad para los profesionales médicos de cara a la toma de decisiones”, indican por su parte los doctores Alfonso Cabello y Felipe Villar, jefes asociados, respectivamente, de los servicios de Medicina Interna y Neumología de la Fundación Jiménez Díaz, también implicados en el proyecto, como el Dr. José María Milicua, jefe asociado de la UCI del hospital madrileño.
En términos de gestión asistencial, el algoritmo ha ayudado a optimizar la eficiencia, al facilitar la agilidad en la actuación sobre los enfermos: “Poder prever la necesidad de determinados recursos con varios días de antelación nos ha permitido adelantarnos a las necesidades de cada momento”, apuntan los especialistas y añaden: “Con respecto a los pacientes, los beneficios del sistema son igualmente claros, al mejorar tanto la experiencia en el hospital como la calidad y seguridad en la atención de su proceso de salud, puesto que se cuenta desde el principio con factores que nos van a indicar su evolución”.
Árbol de decisión de cuatro niveles a partir de las variables clave
A partir de las 20 variables identificadas como relevantes, los integrantes del proyecto realizaron un ajuste empleando árboles de decisión de hasta cuatro niveles de complejidad, de manera que ofrecen una visión global clara de cómo afectaría cada variable al triaje. Concretamente, sobre el conjunto de 20 variables se aplicó el algoritmo Bayesian Ruleset (que calcula la probabilidad de un suceso, teniendo información previa sobre ese suceso), “que proporciona el conjunto de reglas de umbrales que mejor predice la gravedad futura del paciente”, detalla Herrero. “Esto también nos ha servido para validar la idoneidad de estas variables como elementos en clave en la predicción de evolución del paciente”, apostillan los doctores Cabello, Villar y Milicua.
Posteriormente, una vez identificadas las variables relevantes, se entrenaron dos modelos con el objetivo de identificar sendas probabilidades, asociadas a un paciente hospitalizado, de precisar ingreso en UCI o de fallecer. Finalmente, la información del enfermo y sus indicadores analíticos se pasan por estos modelos para obtener las estimaciones correspondientes; unos resultados que se cargan en tiempo real en la base de datos y se integran en la historia clínica del paciente, generando la alerta de predicción respectiva, agilizando y facilitando la toma de decisiones.
Más variables, mejor funcionamiento: un algoritmo en permanente mejora y crecimiento
El algoritmo, en cuyo desarrollo e implementación están implicados los servicios más involucrados en la lucha contra la Covid-19 -Medicina Interna, Neumología, UCI y UCIR (Unidad de Cuidados Intermedios Respiratorios)- de esta red asistencial, además de su Departamento de Big Data, comenzó a implementarse en Urgencias el pasado septiembre, para ampliarse a Hospitalización, UCI y UCIR a mediados de diciembre.
Actualmente todos estos departamentos se benefician del proyecto, pero también lo retroalimentan y mejoran constantemente con el análisis de los resultados en sus pacientes, “lo que ha permitido ampliar la muestra, ajustar los parámetros, incluir nuevas variables y optimizarlas, enriqueciendo y completando permanentemente el algoritmo”, incide el responsable de Big Data de estos cuatro hospitales.
Así, tras entrenar los modelos y ajustarlos a los datos disponibles, se reevaluó la importancia de las variables para cada uno de ellos. “Variables como la edad, el IMC o la fracción inspirado de oxígeno (FiO2) han tenido un peso relevante en ambos modelos de predicción”, explican los doctores Cabello, Villar y Milicua. Y, a corto plazo, añade Herrero, “se espera añadir otras que ayuden a mejorar la precisión de los resultados”.